Where Do Private Models End Up?
Differentially private stochastic gradient descent (DP-SGD) trains private machine learning models by adding noise at each step of the optimization process. Can we achieve privacy by appropriately initializing model weights while adding less noise during DP-SGD? To answer this question, comparing the trajectory of weights and the final models produced by vanilla gradient descent and DP-SGD might be helpful.
I run a simple experiment using the CIFAR10 dataset and convolutional neural networks (2 conv layers, 3 fully connected layers). I first initialize two models with the same weights. I run vanilla gradient descent on the non-private model for 50 epochs and record the weights at the end of each epoch. I repeat this process for the private model using DP-SGD. I visualize the distribution of weights over time for each layer using histograms. If you need to access the experiment code, you can find it in my Colab notebook.
During private training, weight distributions stay closer to initialized weights, while non-private training results in flatter, different distributions. I observed this behavior in both convolutional and fully connected layers. Refer to Figures 1 and 2 for weight distribution trajectories of the first convolutional layer (filter 0) and the third fully connected layer. These observations could be explained by the fact that training samples have less impact on the model weights during private training than non-private training.
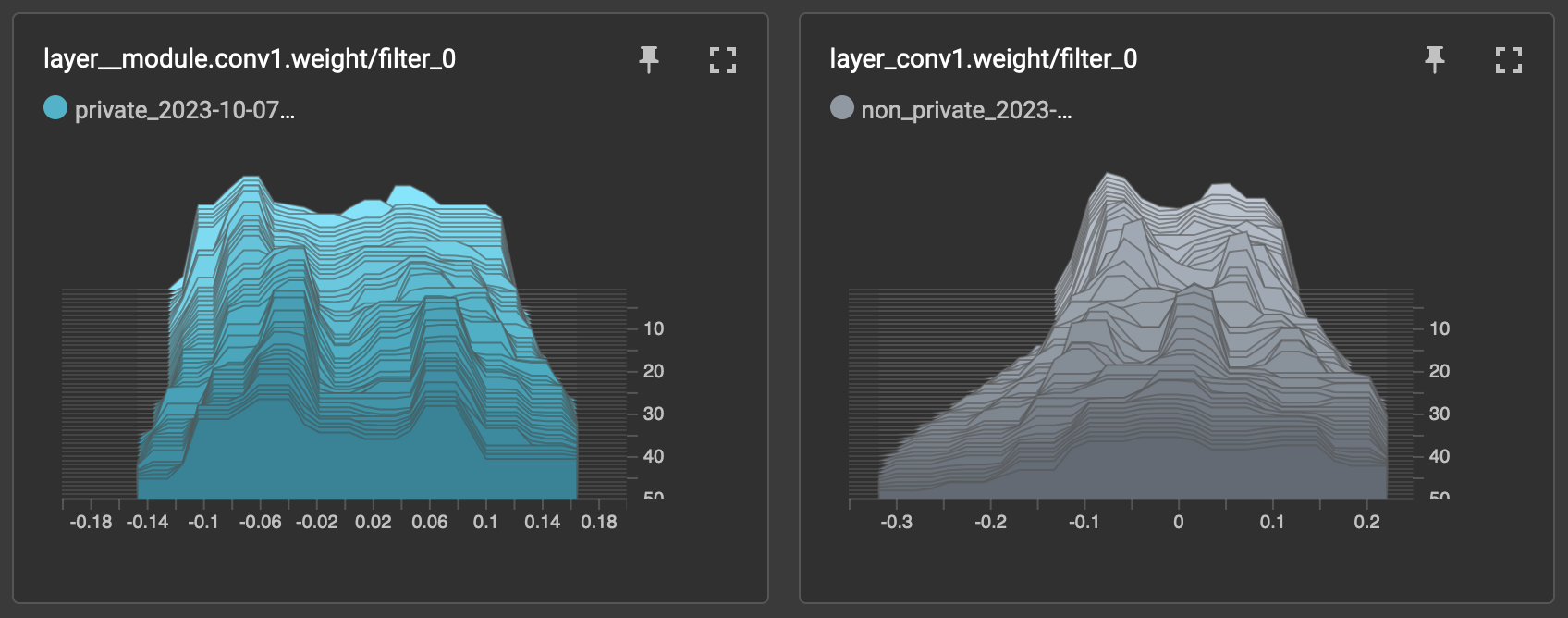
Figure 1: Trajectory of weight distributions for filter 0 of the first convolutional layer of the model. Private model weights are depicted in blue, and non-private model weights are depicted in gray. Note how weights stay closer to the initialized distribution during private training.
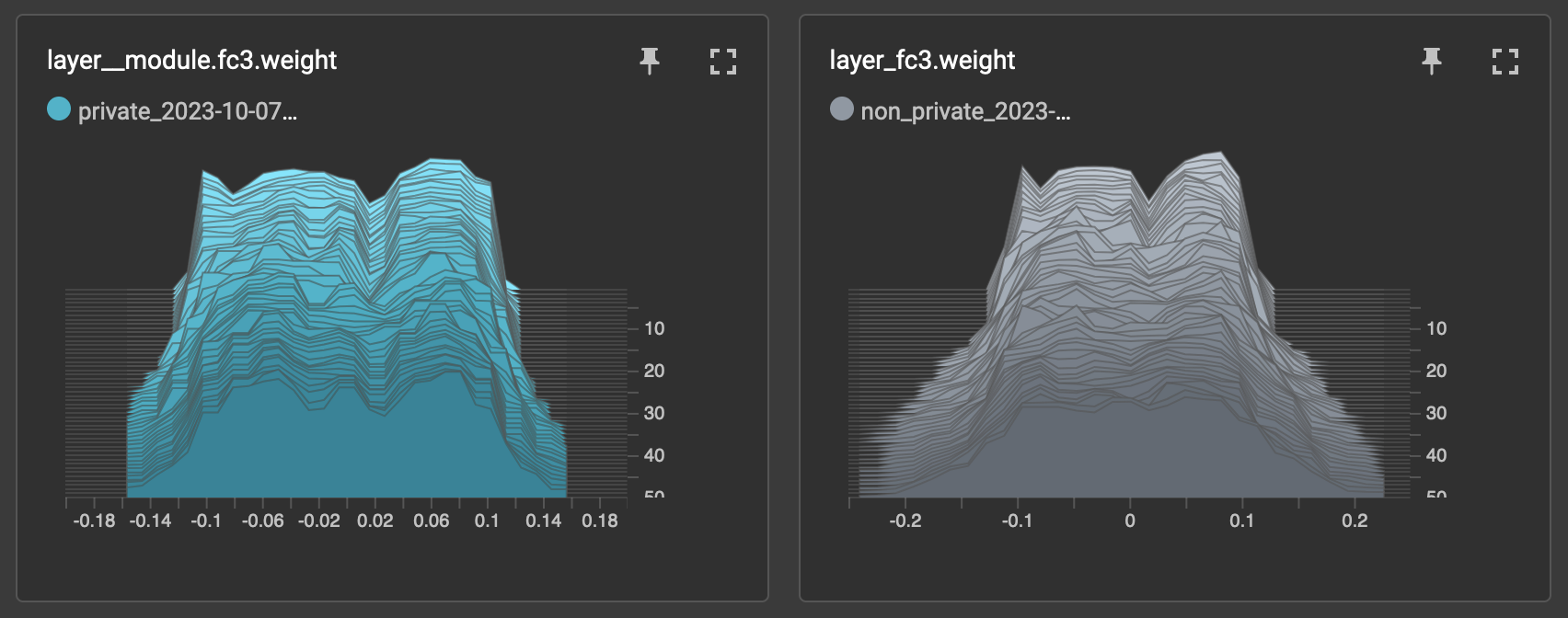
Figure 2: Trajectory of weight distributions for the third fully connected layer of the model. Private model weights are depicted in blue, and non-private model weights are depicted in gray. Note how weights stay closer to the initialized distribution during private training.
Refer to Figure 3 for both models’ training loss over time. At the end of non-private training (50 epochs), the test accuracy of the model was 42.75%. For private training, the test accuracy was 27.68%. The non-private model performs better than the private model, even if they have been trained for the same number of epochs. This may be the reason for the difference in weight distributions. Private training for more epochs may result in similar weight distributions as the non-private model. I will test this hypothesis and update this post soon.
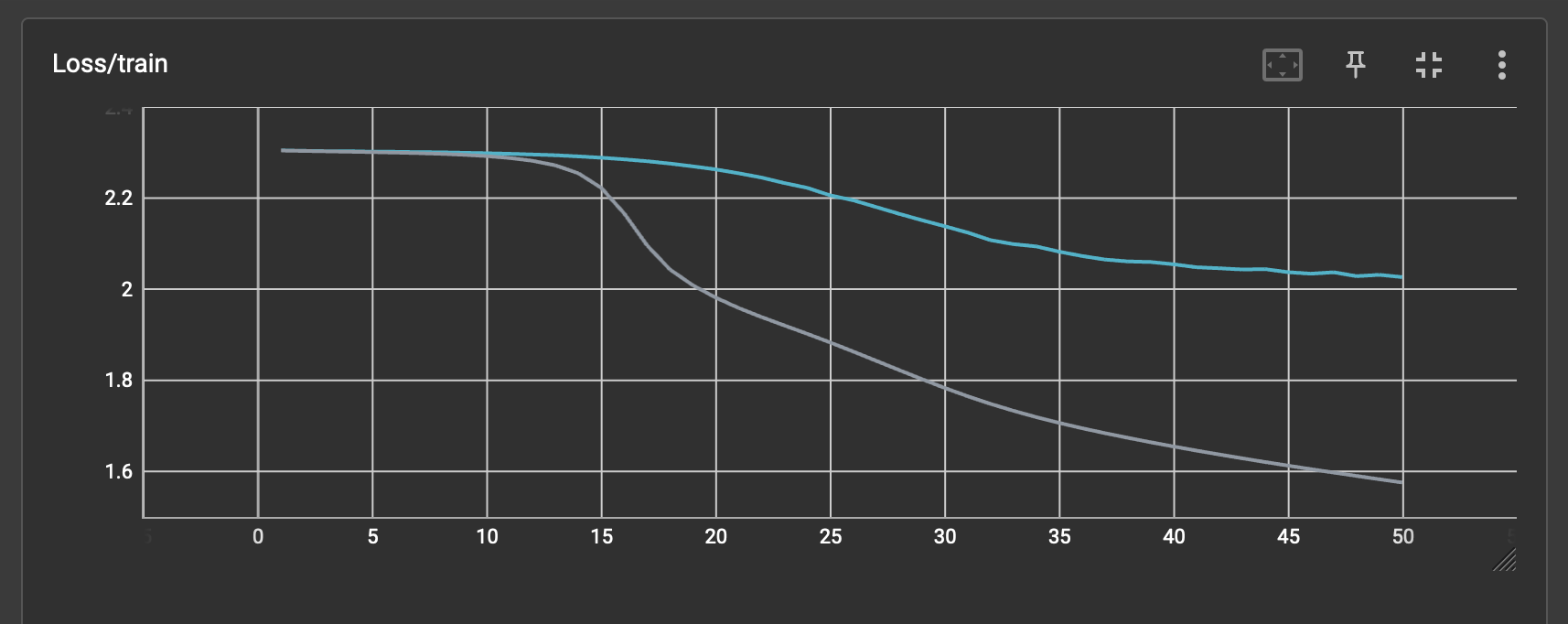
Figure 3: Training loss of the non-private and private models over 50 epochs.
In my Colab notebook, I also check if the non-private and private models are picking up on different patches in the image to make a prediction. I use Local Interpretable Model-Agnostic Explanations (LIME) to do this. As of now, I couldn’t find any noticeable differences between the two models with respect to their explanations. I plan to check the difference between their confidence scores next.
Disclaimer: Please consider these results with caution. I need to run further experiments using more datasets and model architectures to draw conclusive findings. This post aims to check if observable differences exist during non-private and private training. I also wanted to explore how to present these differences meaningfully.
References
Training and testing models using PyTorch: https://pytorch.org/tutorials/beginner/introyt/introyt1_tutorial.html
DP-SGD using Opacus: https://github.com/pytorch/opacus/blob/main/examples/mnist.py
Ribeiro, M. T., Singh, S., & Guestrin, C. (2016). Model-agnostic interpretability of machine learning. arXiv preprint arXiv:1606.05386.
LIME tutorial for images: https://github.com/marcotcr/lime/blob/master/doc/notebooks/Tutorial%20-%20images%20-%20Pytorch.ipynb